前言
复习下Dictionary的一些知识点。
源码地址。
正文
定义
泛型的哈希表, 通过把关键码值映射到表中一个位置来访问数据,以加快查找的速度,是一种键值对关系的集合,底层为两个数组buckets和entries。
成员变量
| 修饰符 | 类型 | 变量名 | 作用简述 |
|---|---|---|---|
| private | int数组 | buckets | hashkey映射数组 |
| private | Entry数组 | entries | 存储所有要查找的值的数组 |
| private | int | count | 容器内当前的元素数量 |
| private | int | version | 数据版本,用于校验对数组的操作是否合法 |
| private | int | freeList | 当前entries中指向的空节点 |
| private | int | freeCount | 空节点数量 |
| private | IEqualityComparer |
comparer | 用于查找时比较hashkey |
| private | KeyCollection | keys | 键集合,惰性生成 |
| private | ValueCollection | values | 值集合,惰性生成 |
| private | Object | _syncRoot | 多线程下使用的同步对象,不过现在基本废弃了, 多线程建议使用ConcurrentDictionary |
Entry结构
1 | private struct Entry { |
虽然数据都是存储在一个名为entries的数组中,但是entry之间的逻辑结构实际上为链表结构, 即相同bucket映射位置的entry会通过next“指针”串联起来。至于为什么不直接用链表,个人猜测是使用数组能够保证一段内存的连续性,而如果使用单一指针指向的不同内存块来构建链表,内存数据会变得更碎片化,更容易cache miss,从而导致访问效率变低。
构造函数
1 | public Dictionary(): this(0, null) {} |
可以看到关键的构造函数主要为以下两个函数,一个预分配容量,一个以另一个键值对容器初始化。
1 | public Dictionary(int capacity, IEqualityComparer<TKey> comparer) |
预分配构造函数将bucket和entries两个数组以capacity大小初始化,而以容器作为参数的构造函数则不停迭代,将参数容器的元素依次Add到新创建的Dictionary当中。comparer为hashkey的查找比较函数,传入null即使用默认比较函数EqualityComparer<TKey>.Default。
扩容机制
扩容的时机与List雷同,即在Insert插入新元素时如果容器元素数量达到上限触发,关键代码如下。
1 | private void Resize() { |
其中扩容调用的是Resize()函数,在通过ExpandPrime函数确定新容量大小后,则会分配重新分配buckets和entries的数组大小,并将数据Copy过去。
减少哈希冲突的优化
在扩容时优化算法来降低哈希冲突: 分配的新容器大小为与 2倍于目前容器容量大小 最接近的最小素数。
1 | public static readonly int[] primes = { |
为什么每次扩容的容量大小都为素数?
关于这个问题可以参考stackoverflow上的讨论以及这篇博客。
结论就是: 在大多数情况下,对于一组数列a(n),如果它数列长度的公因数数量越少,那么该数列中的数字经散列后形成的新数字在哈希表上分布就越均匀,即发生哈希冲突的概率就越小。而素数的公因数为1和它本身,公因数最少,所以每次扩容都尽可能地选择素数作为新容量大小。
哈希冲突过多的优化
在Insert时发生了过多哈希冲突(超过100次)则会调用Resize来重新获取所有hashcode。
1 | if(collisionCount > HashHelpers.HashCollisionThreshold && HashHelpers.IsWellKnownEqualityComparer(comparer)) |
关键函数
主要就查找、添加、删除几个操作相关的函数,并辅以图像说明下。
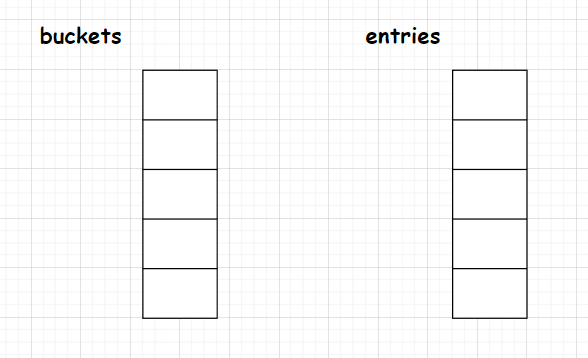
假设先初始化了一个容量大小为5的哈希表
1 | var dict = new Dictionary<string,int>(5); |
那么它的初始结构如下图所示
插入
不管是Add还是操作符[]赋值, 最终都会调用一个Insert函数,代码如下
1 | private void Insert(TKey key, TValue value, bool add) { |
可以看到如果之前并没有预分配容量(buckets为null),那么会先通过Intialize函数给buckets和entries数组分配内存,之后就是调用comapre.GetHashCode分配hashcode,注意这里得到的hashcode要和最大正整数数0x7FFFFFFF进行位且运算来去掉符号位(不能是负数),这样之后通过和buckets的容量大小length进行模除运算就能得到hashcode在buckets数组上映射的位置。之后就是分为两种情况:
- 更新操作, 如果相同
bucket位置的entry存在,并且entry的hashcode与计算后的hashcode一致,而且也不是Add操作,那么就更新entry存储的值,否则就会抛出重复添加元素的异常。 - 插入操作, 会先检查有没有空的
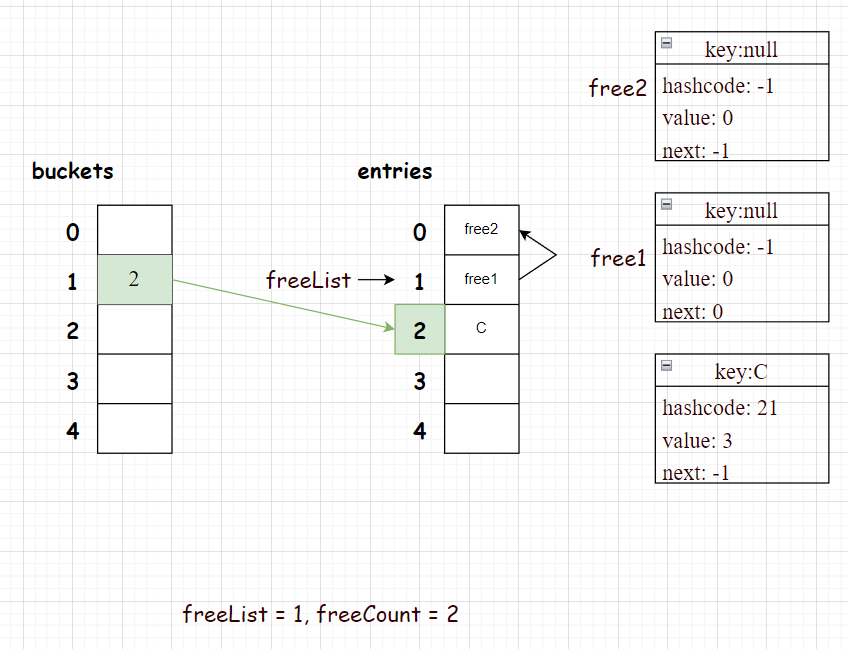
entry节点(FreeCount> 0 ,Remove后留下的所有空节点会串连成一个缓存链表), 如果有空节点那么会优先使用空节点freeList(freeList指向的其实就是缓存链表的头节点),然后使用头插法将其插入对应bucket位置指向的链表,否则就将count加1,然后选用entries[count]位置的节点作为新数据存放节点。之后就是上文提到的判断哈希冲突是否过多从而进行重新哈希的逻辑。
接下来画图举例说明, 假如我们对上文的dict指向多次插入操作,而且它们的hashcode都是21,那么在bucket上映射的位置为1。
1 | dict.Add("A", 1); |
执行上述操作后,结构如下图

删除
删除的逻辑比较简单, 先将key转换为hashcode,然后再转换为buckets中的位置,之后就是遍历bucket位置指向的链表来比较hashcode,如果相等则清除对应位置的entry数据,并将其放入到freelist链表上缓存起来以方便下次Insert操作复用。代码如下:
1 | public bool Remove(TKey key) { |
紧接着上文操作,假设我们执行下列删除操作。
1 | dict.Remove("A"); |
那么结构变化如下图
删除A之后

删除B之后
如果之后又调用了
1 | dict.Add("D", 4) |
那么会将freeList指向的列表头节点复用起来,如果D的HashCode模除不为1,而是在其他位置,比如假设D的HashCode为18,即bucket位置为3。那么操作后的结构如下图

查找
函数GetOrDefault、Contains、TryGetValue等内部都会用到FindEntry来查找对应元素。代码如下:
1 | private int FindEntry(TKey key) { |
核心逻辑就是通过对应的bucket位置找到链表,遍历比较hashcode即可。
所有操作大部分情况下时间复杂度皆为O(1)。
注意ContainsValue未使用映射关系查找,而是从头遍历,因此时间复杂度为O(n)。
1 | public bool ContainsValue(TValue value) { |
使用总结
foreach循环内不要去增删元素。- 如果要批量删除元素,用一个
List存储好要删除的key,然后在List的循环中执行Remove操作。 - 与
List类似的扩容机制,所以在确定容量的情况下尽可能地预分配好空间。 - 避免频繁增删元素,频繁的增删操作会导致
entries的链表逻辑结构顺序变化,foreach的顺序也可能会因此不同。在这种情况下建议换用SortedDictionary。




 。
。