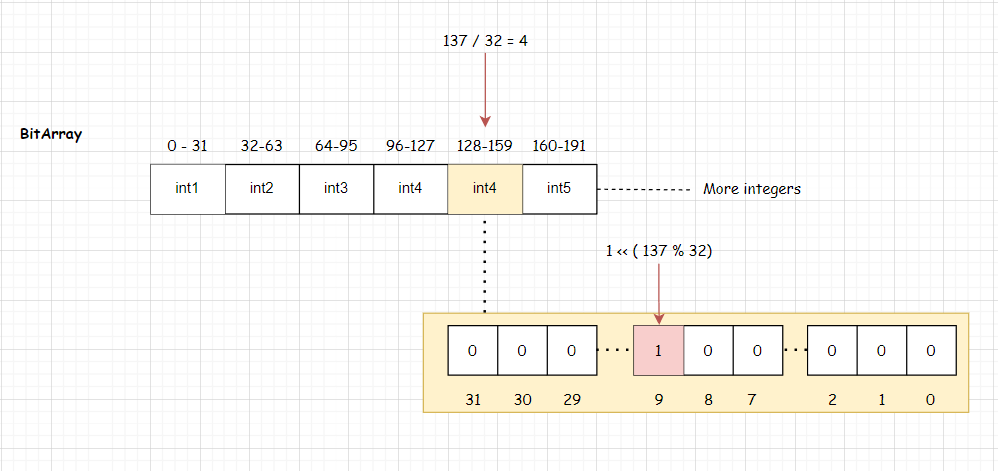
typedefstructProto { CommonHeader; lu_byte numparams; /* number of fixed (named) parameters */ lu_byte is_vararg; lu_byte maxstacksize; /* number of registers needed by this function */ int sizeupvalues; /* size of 'upvalues' */ int sizek; /* size of 'k' */ int sizecode; int sizelineinfo; int sizep; /* size of 'p' */ int sizelocvars; int sizeabslineinfo; /* size of 'abslineinfo' */ int linedefined; /* debug information */ int lastlinedefined; /* debug information */ TValue *k; /* constants used by the function */ Instruction *code; /* opcodes */ structProto **p;/* functions defined inside the function */ Upvaldesc *upvalues; /* upvalue information */ ls_byte *lineinfo; /* information about source lines (debug information) */ AbsLineInfo *abslineinfo; /* idem */ LocVar *locvars; /* information about local variables (debug information) */ TString *source; /* used for debug information */ GCObject *gclist; } Proto;
staticvoidpushclosure(lua_State *L, Proto *p, UpVal **encup, StkId base, StkId ra) { int nup = p->sizeupvalues; Upvaldesc *uv = p->upvalues; int i; LClosure *ncl = luaF_newLclosure(L, nup); ncl->p = p; setclLvalue2s(L, ra, ncl); /* anchor new closure in stack */ for (i = 0; i < nup; i++) { /* fill in its upvalues */ if (uv[i].instack) /* upvalue refers to local variable? */ ncl->upvals[i] = luaF_findupval(L, base + uv[i].idx); else/* get upvalue from enclosing function */ ncl->upvals[i] = encup[uv[i].idx]; luaC_objbarrier(L, ncl, ncl->upvals[i]); } }
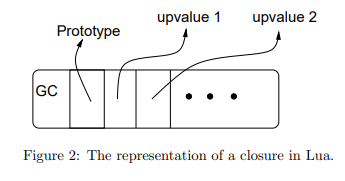
上值Upvalue
Lua闭包实现的核心构成部分是upvalue结构,它表示了一个闭包和一个变量的连接,结构如下。
1 2 3 4 5 6 7 8 9 10 11 12
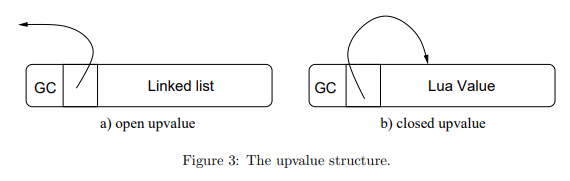
typedefstructUpVal { CommonHeader; lu_byte tbc; /* true if it represents a to-be-closed variable */ TValue *v; /* points to stack or to its own value */ union { struct {/* (when open) */ structUpVal *next;/* linked list */ structUpVal **previous; } open; TValue value; /* the value (when closed) */ } u; } UpVal;
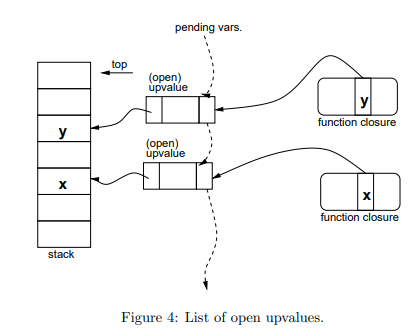
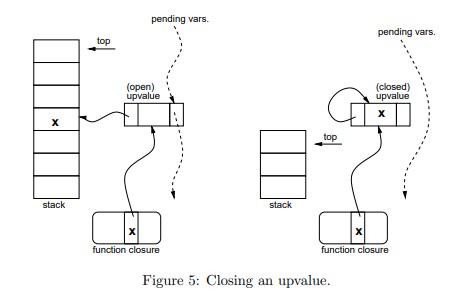
intluaF_close(lua_State *L, StkId level, int status) { UpVal *uv; while ((uv = L->openupval) != NULL && uplevel(uv) >= level) { TValue *slot = &uv->u.value; /* new position for value */ lua_assert(uplevel(uv) < L->top); if (uv->tbc && status != NOCLOSINGMETH) { /* must run closing method, which may change the stack */ ptrdiff_t levelrel = savestack(L, level); status = callclosemth(L, uplevel(uv), status); level = restorestack(L, levelrel); } luaF_unlinkupval(uv); setobj(L, slot, uv->v); /* move value to upvalue slot */ uv->v = slot; /* now current value lives here */ if (!iswhite(uv)) gray2black(uv); /* closed upvalues cannot be gray */ luaC_barrier(L, uv, slot); } return status; }
privatevoidEnsureCapacity(int min) { int newCapacity = keys.Length == 0? _defaultCapacity: keys.Length * 2; // Allow the list to grow to maximum possible capacity (~2G elements) before encountering overflow. // Note that this check works even when _items.Length overflowed thanks to the (uint) cast if ((uint)newCapacity > MaxArrayLength) newCapacity = MaxArrayLength; if (newCapacity < min) newCapacity = min; Capacity = newCapacity; }
关键函数
查找
一般是根据key来找值,当然也支持通过数组下标来找值,使用ValueList[idx]访问即可。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
publicintIndexOf(TKey key) { if (((Object) key) == null) ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key); int i = Array.BinarySearch<TKey>(_dict.keys, 0, _dict.Count, key, _dict.comparer); if (i >= 0) return i; return-1; }
public TValue this[TKey key] { get { int i = IndexOfKey(key); if (i >= 0) return values[i]; ThrowHelper.ThrowKeyNotFoundException(); returndefault(TValue); } set { if (((Object) key) == null) ThrowHelper.ThrowArgumentNullException(ExceptionArgument.key); int i = Array.BinarySearch<TKey>(keys, 0, _size, key, comparer); if (i >= 0) { values[i] = value; version++; return; } Insert(~i, key, value); } }
internalstruct Slot { internalint hashCode; // Lower 31 bits of hash code, -1 if unused internalint next; // Index of next entry, -1 if last internal T value; }
privatevoidIncreaseCapacity() { Debug.Assert(m_buckets != null, "IncreaseCapacity called on a set with no elements"); int newSize = HashHelpers.ExpandPrime(m_count); if (newSize <= m_count) { thrownew ArgumentException(SR.GetString(SR.Arg_HSCapacityOverflow)); } // Able to increase capacity; copy elements to larger array and rehash SetCapacity(newSize, false); } ///<summary> /// Set the underlying buckets array to size newSize and rehash. Note that newSize /// *must* be a prime. It is very likely that you want to call IncreaseCapacity() /// instead of this method. ///</summary> privatevoidSetCapacity(int newSize, bool forceNewHashCodes) { Contract.Assert(HashHelpers.IsPrime(newSize), "New size is not prime!"); Contract.Assert(m_buckets != null, "SetCapacity called on a set with no elements"); Slot[] newSlots = new Slot[newSize]; if (m_slots != null) { Array.Copy(m_slots, 0, newSlots, 0, m_lastIndex); } if(forceNewHashCodes) { for(int i = 0; i < m_lastIndex; i++) { if(newSlots[i].hashCode != -1) { newSlots[i].hashCode = InternalGetHashCode(newSlots[i].value); } } } int[] newBuckets = newint[newSize]; for (int i = 0; i < m_lastIndex; i++) { int bucket = newSlots[i].hashCode % newSize; newSlots[i].next = newBuckets[bucket] - 1; newBuckets[bucket] = i + 1; } m_slots = newSlots; m_buckets = newBuckets; }
publicvoidIntersectWith(IEnumerable<T> other) { if (other == null) { thrownew ArgumentNullException("other"); } Contract.EndContractBlock(); // intersection of anything with empty set is empty set, so return if count is 0 if (m_count == 0) { return; } // if other is empty, intersection is empty set; remove all elements and we're done // can only figure this out if implements ICollection<T>. (IEnumerable<T> has no count) ICollection<T> otherAsCollection = other as ICollection<T>; if (otherAsCollection != null) { if (otherAsCollection.Count == 0) { Clear(); return; } HashSet<T> otherAsSet = other as HashSet<T>; // faster if other is a hashset using same equality comparer; so check // that other is a hashset using the same equality comparer. if (otherAsSet != null && AreEqualityComparersEqual(this, otherAsSet)) { IntersectWithHashSetWithSameEC(otherAsSet); return; } } IntersectWithEnumerable(other); }
///<summary> /// If other is a hashset that uses same equality comparer, intersect is much faster /// because we can use other's Contains ///</summary> ///<param name="other"></param> privatevoidIntersectWithHashSetWithSameEC(HashSet<T> other) { for (int i = 0; i < m_lastIndex; i++) { if (m_slots[i].hashCode >= 0) { T item = m_slots[i].value; if (!other.Contains(item)) { Remove(item); } } } }
///<summary> /// Iterate over other. If contained in this, mark an element in bit array corresponding to /// its position in m_slots. If anything is unmarked (in bit array), remove it. /// /// This attempts to allocate on the stack, if below StackAllocThreshold. ///</summary> ///<param name="other"></param> [System.Security.SecuritySafeCritical] privateunsafevoidIntersectWithEnumerable(IEnumerable<T> other) { Debug.Assert(m_buckets != null, "m_buckets shouldn't be null; callers should check first"); // keep track of current last index; don't want to move past the end of our bit array // (could happen if another thread is modifying the collection) int originalLastIndex = m_lastIndex; int intArrayLength = BitHelper.ToIntArrayLength(originalLastIndex); BitHelper bitHelper; if (intArrayLength <= StackAllocThreshold) { int* bitArrayPtr = stackallocint[intArrayLength]; bitHelper = new BitHelper(bitArrayPtr, intArrayLength); } else { int[] bitArray = newint[intArrayLength]; bitHelper = new BitHelper(bitArray, intArrayLength); } // mark if contains: find index of in slots array and mark corresponding element in bit array foreach (T item in other) { int index = InternalIndexOf(item); if (index >= 0) { bitHelper.MarkBit(index); } } // if anything unmarked, remove it. Perf can be optimized here if BitHelper had a // FindFirstUnmarked method. for (int i = 0; i < originalLastIndex; i++) { if (m_slots[i].hashCode >= 0 && !bitHelper.IsMarked(i)) { Remove(m_slots[i].value); } } }
///<summary> /// Used internally by set operations which have to rely on bit array marking. This is like /// Contains but returns index in slots array. ///</summary> ///<param name="item"></param> ///<returns></returns> privateintInternalIndexOf(T item) { Debug.Assert(m_buckets != null, "m_buckets was null; callers should check first"); int hashCode = InternalGetHashCode(item); for (int i = m_buckets[hashCode % m_buckets.Length] - 1; i >= 0; i = m_slots[i].next) { if ((m_slots[i].hashCode) == hashCode && m_comparer.Equals(m_slots[i].value, item)) { return i; } } // wasn't found return-1; }
publicvoidExceptWith(IEnumerable<T> other) { if (other == null) { thrownew ArgumentNullException("other"); } Contract.EndContractBlock(); // this is already the enpty set; return if (m_count == 0) { return; } // special case if other is this; a set minus itself is the empty set if (other == this) { Clear(); return; } // remove every element in other from this foreach (T element in other) { Remove(element); } }
publicvoidSymmetricExceptWith(IEnumerable<T> other) { if (other == null) { thrownew ArgumentNullException("other"); } Contract.EndContractBlock(); // if set is empty, then symmetric difference is other if (m_count == 0) { UnionWith(other); return; } // special case this; the symmetric difference of a set with itself is the empty set if (other == this) { Clear(); return; } HashSet<T> otherAsSet = other as HashSet<T>; // If other is a HashSet, it has unique elements according to its equality comparer, // but if they're using different equality comparers, then assumption of uniqueness // will fail. So first check if other is a hashset using the same equality comparer; // symmetric except is a lot faster and avoids bit array allocations if we can assume // uniqueness if (otherAsSet != null && AreEqualityComparersEqual(this, otherAsSet)) { SymmetricExceptWithUniqueHashSet(otherAsSet); } else { SymmetricExceptWithEnumerable(other); } }
publicboolIsSubsetOf(IEnumerable<T> other) { if (other == null) { thrownew ArgumentNullException("other"); } Contract.EndContractBlock(); // The empty set is a subset of any set if (m_count == 0) { returntrue; } HashSet<T> otherAsSet = other as HashSet<T>; // faster if other has unique elements according to this equality comparer; so check // that other is a hashset using the same equality comparer. if (otherAsSet != null && AreEqualityComparersEqual(this, otherAsSet)) { // if this has more elements then it can't be a subset if (m_count > otherAsSet.Count) { returnfalse; } // already checked that we're using same equality comparer. simply check that // each element in this is contained in other. return IsSubsetOfHashSetWithSameEC(otherAsSet); } else { ElementCount result = CheckUniqueAndUnfoundElements(other, false); return (result.uniqueCount == m_count && result.unfoundCount >= 0); } }
[System.Security.SecuritySafeCritical] privateunsafe ElementCount CheckUniqueAndUnfoundElements(IEnumerable<T> other, bool returnIfUnfound) { ElementCount result; // need special case in case this has no elements. if (m_count == 0) { int numElementsInOther = 0; foreach (T item in other) { numElementsInOther++; // break right away, all we want to know is whether other has 0 or 1 elements break; } result.uniqueCount = 0; result.unfoundCount = numElementsInOther; return result; } Debug.Assert((m_buckets != null) && (m_count > 0), "m_buckets was null but count greater than 0"); int originalLastIndex = m_lastIndex; int intArrayLength = BitHelper.ToIntArrayLength(originalLastIndex); BitHelper bitHelper; if (intArrayLength <= StackAllocThreshold) { int* bitArrayPtr = stackallocint[intArrayLength]; bitHelper = new BitHelper(bitArrayPtr, intArrayLength); } else { int[] bitArray = newint[intArrayLength]; bitHelper = new BitHelper(bitArray, intArrayLength); } // count of items in other not found in this int unfoundCount = 0; // count of unique items in other found in this int uniqueFoundCount = 0; foreach (T item in other) { int index = InternalIndexOf(item); if (index >= 0) { if (!bitHelper.IsMarked(index)) { // item hasn't been seen yet bitHelper.MarkBit(index); uniqueFoundCount++; } } else { unfoundCount++; if (returnIfUnfound) { break; } } } result.uniqueCount = uniqueFoundCount; result.unfoundCount = unfoundCount; return result; }
publicboolIsProperSubsetOf(IEnumerable<T> other) { if (other == null) { thrownew ArgumentNullException("other"); } Contract.EndContractBlock(); ICollection<T> otherAsCollection = other as ICollection<T>; if (otherAsCollection != null) { // the empty set is a proper subset of anything but the empty set if (m_count == 0) { return otherAsCollection.Count > 0; } HashSet<T> otherAsSet = other as HashSet<T>; // faster if other is a hashset (and we're using same equality comparer) if (otherAsSet != null && AreEqualityComparersEqual(this, otherAsSet)) { if (m_count >= otherAsSet.Count) { returnfalse; } // this has strictly less than number of items in other, so the following // check suffices for proper subset. return IsSubsetOfHashSetWithSameEC(otherAsSet); } } ElementCount result = CheckUniqueAndUnfoundElements(other, false); return (result.uniqueCount == m_count && result.unfoundCount > 0); }
publicboolIsSupersetOf(IEnumerable<T> other) { if (other == null) { thrownew ArgumentNullException("other"); } Contract.EndContractBlock(); // try to fall out early based on counts ICollection<T> otherAsCollection = other as ICollection<T>; if (otherAsCollection != null) { // if other is the empty set then this is a superset if (otherAsCollection.Count == 0) { returntrue; } HashSet<T> otherAsSet = other as HashSet<T>; // try to compare based on counts alone if other is a hashset with // same equality comparer if (otherAsSet != null && AreEqualityComparersEqual(this, otherAsSet)) { if (otherAsSet.Count > m_count) { returnfalse; } } } return ContainsAllElements(other); }
publicboolIsProperSupersetOf(IEnumerable<T> other) { if (other == null) { thrownew ArgumentNullException("other"); } Contract.EndContractBlock(); // the empty set isn't a proper superset of any set. if (m_count == 0) { returnfalse; } ICollection<T> otherAsCollection = other as ICollection<T>; if (otherAsCollection != null) { // if other is the empty set then this is a superset if (otherAsCollection.Count == 0) { // note that this has at least one element, based on above check returntrue; } HashSet<T> otherAsSet = other as HashSet<T>; // faster if other is a hashset with the same equality comparer if (otherAsSet != null && AreEqualityComparersEqual(this, otherAsSet)) { if (otherAsSet.Count >= m_count) { returnfalse; } // now perform element check return ContainsAllElements(otherAsSet); } } // couldn't fall out in the above cases; do it the long way ElementCount result = CheckUniqueAndUnfoundElements(other, true); return (result.uniqueCount < m_count && result.unfoundCount == 0); }
集合重叠
判断两个集合是否重叠,与求交集逻辑类似,不同的是两个集合只要发现有一个共有的元素就可以结束遍历了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
publicboolOverlaps(IEnumerable<T> other) { if (other == null) { thrownew ArgumentNullException("other"); } Contract.EndContractBlock(); if (m_count == 0) { returnfalse; } foreach (T element in other) { if (Contains(element)) { returntrue; } } returnfalse; }